机器之心编辑部
2026年AI的进化,势必会超过我们的想象。
1月10日下午,在由清华大学基础模型北京市重点实验室、智谱AI发起的AGI-Next前沿峰会上,汇聚了刚刚上市两天的智谱、领跑独角兽月之暗面、全球开源大模型顶流Qwen的创始人、CEO和负责人。
智谱AI的唐杰、月之暗面的杨植麟、阿里云通义千问的林俊旸等正处于聚光灯下的中国大模型掌舵者,以及张钹院士、杨强等学界泰斗罕见地同台亮相。
刚刚履新腾讯AI首席科学家、曾以「思维树」(TreeofThoughts)和《AI下半场》闻名的姚顺雨,也在此迎来了回国后的对外首秀。

本周国内AI创业公司接连上市,DeepSeek又刚刚曝出即将发布全新一代大模型,人工智能的热度还在持续升温,但另一方面,AI技术似乎来到了一个临界点:一边是大规模预训练(Pre-training)、强化学习对齐(Alignment/RLHF)等范式带来的爆发期即将结束,另一方面,新的提升范式似乎还未启动。
如果说2025年的大模型技术以一种近乎「暴力美学」的方式撕开了AGI大门的一角,那么2026年开年这场峰会,就像是一次冷静后的复盘与再出发。
无论是演讲时的独白,还是圆桌上的激辩,几位掌舵者目及的方向不约而同:从「聊天机器人」进化为「干活的智能体」;从单纯堆砌算力转向追求AI「自我学习」的新探索;让AI从预测下一个词,变为真正理解并改变物理世界的智能生命体。
但与此同时,他们给出的解法却各不相同。
这场峰会传递出一个清晰的信号:单纯的参数竞赛已成过去,前沿公司和团队正在扎堆进入新航路。
唐杰:让机器像人一样「思考」与「做梦」
作为学术界与产业界的双重代表,清华大学计算机系教授、智谱创立发起人兼首席科学家唐杰教授将大模型的进化比作人类认知的成长过程。他回顾了AI的发展历程,认为我们正在从「系统1」(基于直觉的快思考)向「系统2」(基于逻辑的慢思考)进化。
唐杰抛出了一个引人深思的观点:「Scaling可能是一个最轻松的办法,是我们人类偷懒的办法。」他认为,单纯依靠堆砌数据和算力的已知Scaling路径虽然有效,但更本质的方法可能是找到新的知识压缩方式,探索未知的Scaling范式。
为此,他重点介绍了RLVR(ReinforcementLearningwithVerifiableRewards,可验证奖励的强化学习)。在数学、编程等「可验证」的场景下,模型可以通过自我探索突飞猛进。智谱AI最新的GLM-4.7正是这一思路的产物,它在Coding和Agent任务上展现了惊人的能力。但唐杰也坦承,未来的挑战在于如何将这种能力扩展到「半自动验证」甚至「不可验证」的广阔领域。
在移动端Agent方面,唐杰展示了AutoGLM的野心。未来的AI不应该只是一个聊天框,而应该是一个渗透到设备底层的幽灵。他们采用了一种「API+GUI」的混合模式:对AI友好的环节走API,对人类友好的环节则模拟人手点击GUI(图形用户界面)。演示中,AutoGLM可以在手机后台静默执行长达40步的复杂操作——从查询攻略、打开地图、比价、到最终下单订票,一气呵成。
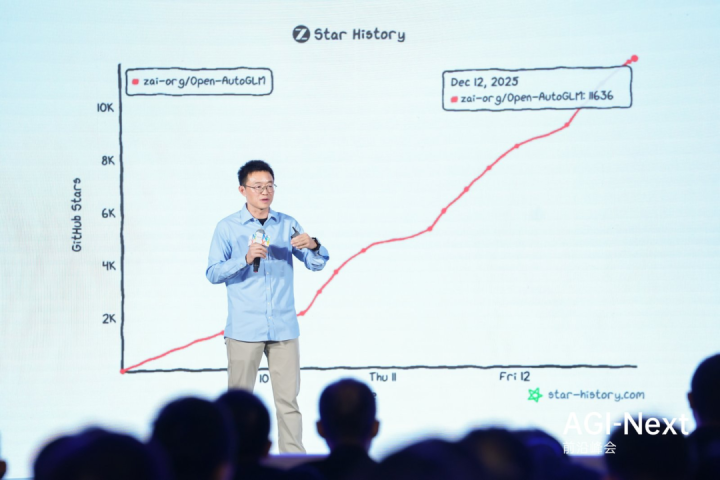
演讲中一大迷人的部分在于唐杰对「机器睡眠」的构想。他认为人脑之所以聪明,是因为有睡眠机制,在无意识中整理记忆、进行自学习。未来的AI也应该具备类似的机制,通过「自反思」和「自学习」来消化数据,而不仅仅是被动地接受训练。他强调,如果没有这种机制,人类的长期记忆可能只是一堆噪音,无法转化为真正的知识。

尽管中国开源模型在2025年席卷了各大榜单,前五名几乎被中国模型包揽,但唐杰依然保持着清醒。他提醒道,我们是在开源的游乐场里玩得很高兴,但与顶尖闭源模型的实际差距可能并没有想象中那么小。只有去探索那些未知的Scaling范式,才能真正缩小这一差距。
杨植麟:智能是不可替代的Token,我们在寻找最美的Loss曲线

一如既往,杨植麟的演讲充满了第一性原理的极客浪漫。这位90后创始人没有过多罗列商业数字,而是将大模型的发展回归到最本质的物理规律。他认为从2019年至今,所有大模型的第一性原理依然是ScalingLaw,这本质上是一个「将能源转换为智能」的过程。如果拥有更好的芯片、更优的架构,就能以更少的能源置换出更高级的智能。
他特别提到了Kaplan早期的经典论文,对比了Transformer与LSTM在ScalingLaw下的表现。
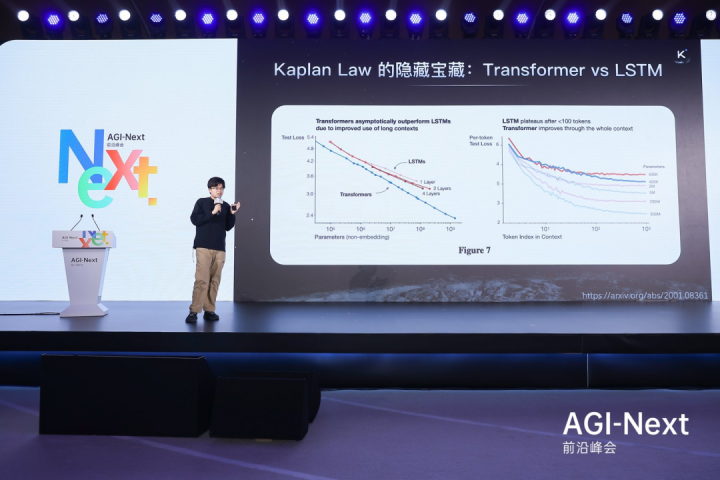
在短Context(上下文)下,两者差异不大;但当Context拉长到1000甚至更长时,Transformer的优势才显露无遗。这种「长程优势」,正是Agent(智能体)时代的胜负手。因为很多Agent任务本质上是搜索问题,而更好的预训练模型能提供更强的先验,帮助我们在茫茫的搜索空间中快速剪枝。
为了追求极致的「TokenEfficiency」(Token效率),杨植麟展示了月之暗面在2025年的两大杀手锏。首先是Muon优化器。

相比于统治了业界十年的Adam优化器,这个全新的二阶优化器实现了「两倍的Token效率提升」。这意味着,达到同样的智能水平,它只需要一半的数据量。为了解决二阶优化器常见的训练不稳定问题,团队引入了创新的「QKClip」机制,动态调整梯度。杨植麟指着屏幕上一张完全平稳下降、没有任何毛刺(spike)的Loss曲线图,动情地说道:「这张图是我2025年见过的最美的东西,它是一个完全平稳下降的Loss曲线。当你有一个优雅的方法,就可以得到一个优雅的结果。」
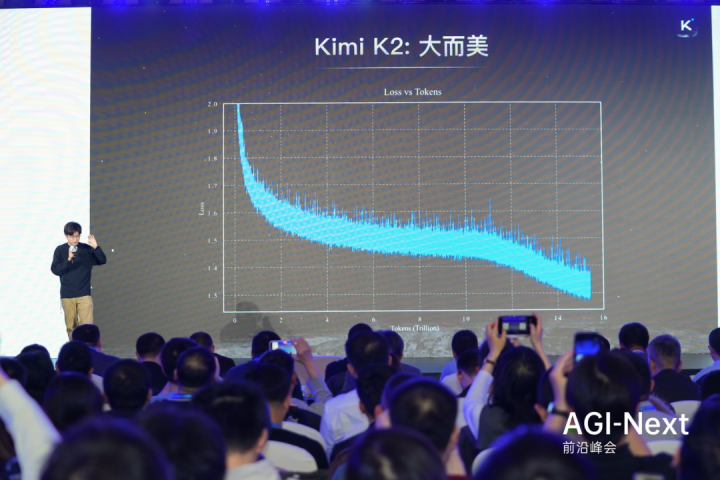
另一个突破则是Key-ValueCrossAttention。针对长上下文任务,这种新架构不仅克服了传统线性注意力在长距离任务上「掉点」的顽疾,甚至在超长Context下的表现超越了全注意力(FullAttention)机制,且速度提升了6到10倍。
在演讲的最后,杨植麟谈到了AGI的「品味」。
他认为做模型本质上是在创造一种世界观。智能与电力不同,电力是同质化的,深圳的一度电和北京的一度电没有区别;但智能是非同质化的,一位音乐家产生的智能与一位程序员产生的智能截然不同。他透露,基于这些理念打造的KimiK2模型,在极高难度的HLE(Humanity'sLastExam)基准测试中达到了45%的准确率,超越了OpenAI等美国前沿公司。
面对AI可能带来的风险,他引用了Kimi给他的回答:这不仅是工具,更是人类认知的延伸,我们不应因恐惧而停滞不前,放弃人类文明的上限。
林俊旸:通往通用智能体(GeneralAgent)之路

阿里云通义千问(Qwen)的林俊旸则带来了一股浓厚的产品主义气息。作为开源界的「卷王」,他直言「模型即产品」,并分享了Qwen如何通过开源社区的反馈完成自我进化的故事。
针对2026年的主力模型Qwen-3,林俊旸透露团队正在全力打磨HybridArchitecture(混合架构)。
这种架构极有可能是将Transformer与Mamba或类似的线性注意力机制以3:1的比例混合,旨在解决无限长文本(InfiniteLongContext)带来的显存和计算瓶颈。他特别自豪地提到了「不降质」的突破——在增强视觉和语音能力的同时,模型的文本推理能力不再像过去那样出现倒退,真正实现了多模态与智力的同步提升。
「人有眼睛和耳朵才能更好地理解世界,模型也一样。」林俊旸展示了Qwen在Omni(全能)模型上的进展。
他放出了两张对比图,一张是8月份生成的「AI味」浓重的图片,另一张是12月份生成的「宿舍女生自拍」风格图片,后者逼真程度令人咋舌。

更重要的是,Qwen正在尝试将「生成」与「理解」打通。例如在解几何题时,如果模型卡住了,它可以自己画一条辅助线(生成),然后基于这张新图继续推理(理解)。这种「理解-生成一体化」被林俊旸视为通向AGI的重要台阶。
林俊旸还分享了一个关于开源社区「反哺」的有趣案例。用户曾反馈图片编辑功能中「手放下来位置歪了」的问题,这让团队意识到即使是微小的像素级偏移,在真实应用中也是不可接受的。这种算法与Infra(基础设施)的联合优化,让Qwen在迭代速度上保持了惊人的优势。
对于AI的未来,林俊旸的愿景非常接地气:「如果你的想法不是帮助全人类,那不如不做大模型。」他希望未来的模型不仅仅是通过考试的学霸,更是一个能真正帮助人类的Agent。他观察到旧金山已经进入了VibeCoding(氛围编程)时代,没人再手写代码,而国内尚未普及。他坚信,能够操作电脑、写代码、甚至在物理世界里端茶倒水的EmbodiedAI(具身智能)才是AI走向现实世界的终极形态。
圆桌激辩:从硅谷的富人创新到Agent的终局
如果说演讲环节是各位掌舵者对自家技术版图的宣示,那么随后的圆桌对话则是一场卸下防备的坦白局。
这场对话的阵容堪称豪华:学界泰斗杨强、刚刚履新腾讯AI首席科学家的姚顺雨(线上参加,这也是姚顺雨告别DeepMind和OpenAI加入腾讯后的首次公开露面)、通义千问负责人林俊旸,以及智谱AICEO唐杰。

在主持人的追问下,四位嘉宾围绕模型分化、下一代范式、Agent的商业落地以及中美AI差距等敏感话题,展开了一场超过70分钟的思想交锋。
ToC的温吞与ToB的激进:姚顺雨的首秀观察
作为横跨中美、经历过OpenAI核心研发团队的科学家,姚顺雨的视角显得尤为犀利。对于当前大模型在ToC(面向消费者)和ToB(面向企业)市场的表现,他给出了一个极其鲜明的判断:ToC端的体验正在趋于平缓,而ToB端的生产力革命已经发生。
「大家都有一个感觉,今天用ChatGPT和去年用ChatGPT,对大部分人大部分时候其实感受的变化已经没有那么强烈了。」姚顺雨直言不讳。对于普通用户来说,模型在抽象代数或范畴论上的能力提升是「无感」的,它更像是一个搜索引擎的加强版。但ToB领域则完全不同,尤其是Coding场景,「Coding革命已经开始,它正在重复整个计算机行业做事的方式——不再写代码,而是用英语和电脑交流。」
他用一个生动的例子解释了为什么企业愿意为最强的模型支付溢价:如果一个员工年薪20万美元,每天处理10个任务。顶级模型(如OpenAIo1)能做对9个,而差一点的模型只能做对5个。「问题在于你不知道错的那5个是哪5个。」在这种情况下,企业宁愿支付高昂的溢价来换取确定性。因此,姚顺雨预判:「在ToB市场上,强模型和弱模型的分化会变得越来越明显。」
对于这一观点,阿里云的林俊旸表示认同,他还从「基因」的角度解读一下。对于姚顺雨的「腾讯肯定还是ToC基因更强的公司」的看法,他半开玩笑地说道:「顺雨到了腾讯,腾讯可能就变成了有顺雨基因的公司。」他认为,无论是ToB还是ToC,最终服务的都是真实的人类,关键在于能否解决长尾问题。
下一个范式:是「间谍」还是「核爆」?
当话题转向2026年可能出现的技术范式转移时,自主学习(Self-learning)成为了全场共识的关键词。但这个范式将以何种面貌出现?
姚顺雨提供了一个非常独特的视角。他认为自主学习可能不会像AlphaGo那样以「平地惊雷」的方式出现,而更像是一个「潜伏的间谍」。
「这个事情其实已经在发生了。」姚顺雨指出,ChatGPT利用用户数据不断拟合聊天风格,ClaudeCode编写了自己项目95%的代码,这些都是自主学习的雏形。他将未来的AI系统比作两部分:一部分是神经网络(大脑),另一部分是调用这个神经网络的代码库(身体)。当有一天,AI开始自己编写那部分「调用自己的代码」时,质变就会发生。「这可能更像是一个间谍渗透的过程,而不是一次突发的突破。」
对此,智谱AI的唐杰则表现得更加审慎。他坦言自己对2026年出现巨大的范式革新持怀疑态度。他提出了「智能效率」(IntelligenceEfficiency)的概念,即投入多少资源能获得多少智能增量。目前的Scaling虽然有效,但本质上是「最笨的方法」。真正的范式革命,应该是找到一种能用极少投入换取巨大智能增量的新路径。
林俊旸则从安全角度表达了对「主动性AI」的担忧。「我最担心的不是AI学了什么,而是它主动做了一些该做或是不该做的事。」他举例说,如果AI主动发现会场有个炸弹,这固然是好事;但如果它产生了其他不可控的主动意图,这将是巨大的安全隐患。
Agent的终局:从工具到「职场人」
对于2026年被寄予厚望的Agent(智能体),杨强教授提出了一个清晰的四阶段演进论:
目标和规划都由人定义;
目标由人定义,规划由AI辅助;
AI观察人的工作流程(ProcessData),自动学习规划;
终极阶段:目标和规划都由大模型内生定义。
目前的Agent大多处于第一、二阶段。姚顺雨认为,Agent要真正产生经济价值,瓶颈往往不在模型本身,而在环境和教育。他在ScaleAI实习的经历让他意识到,即使模型能力不再提升,仅靠将现有模型部署到各种企业环境中,就能产生巨大的经济效益。
「人和人的差距正在拉大,不是AI替代了人的工作,而是会使用工具的人在替代不会使用工具的人。」姚顺雨发出了这样的呼吁。他认为,当下中国最有意义的事情之一,就是教育公众如何更好地使用AI工具,填平这道认知鸿沟。
林俊旸则补充了长尾理论。他认为Agent的核心价值在于解决那些通用模型无法覆盖的、极其个性化的长尾需求。「如果我寻遍各处都找不到解决方案,但在那一刻,AI帮我解决了,这就是AI最大的魅力。」
中美差距的灵魂拷问:胜算如何
圆桌的高潮出现在最后一个话题:3到5年后,全球最领先的AI公司是一家中国公司的概率有多大?
林俊旸认为比较困难,他给出的理由却发人深省。他将其比作美国的「富人创新」与中国的「穷人创新」。
硅谷拥有顶级的显卡储备,甚至在有些浪费地使用算力探索下一代范式;而中国团队往往是在资源受限的情况下,被逼出了极致的算法优化和工程落地能力。「穷则思变,创新往往也发生在资源受限的地方。」林俊旸认为,软硬结合(如AI与MCU芯片的结合)或许是中国突围的一个机会。
姚顺雨对此则更为乐观。他认为,硬件(如光刻机)的瓶颈是客观且可解决的,真正的差距在于主观的冒险精神和研究文化。
「在中国,大家还是更喜欢做安全的事情。如果这个事情已经被证明可以做出来,我们几个月就能复现并做到极致。但如果让你去探索一个未知的领域,比如长期记忆,大家就会犹豫。」姚顺雨犀利地指出了中国研究界的痛点:过分关注榜单和数字,而忽视了什么是正确的事情。
他回忆起在OpenAI和DeepMind的经历,那里的人更在乎「能不能创造出新的东西」,而不是「能不能在榜单上高出一分」。他呼吁中国的研究者走出榜单的束缚,「DeepSeek做得就很好,他们没有那么关注榜单,而是关注用户体验和什么是正确的技术路径。」
唐杰教授则以「最不幸的一代」自嘲:上有老一辈学者还在工作,下有00后天才少年横空出世,夹在中间的80后、90后研究者好像被「无缝跳过了」,世界已经交给下一代了。但他同时指出,中国00后一代展现出的冒险精神令人欣慰。
「如果在这个时间点,有一群聪明人真的愿意做特别冒险的事,而且国家能提供更好的容错环境,哪怕概率只有20%,我们也有机会抓住那个三五年一遇的窗口期。」唐杰最后总结道。
尾声:未完成的答卷
这场圆桌对话并没有给出一个确定的答案,却留下了一份沉甸甸的思考。
从姚顺雨对「榜单文化」的批判,到林俊旸对「富人创新」的羡慕与不甘,再到杨强和唐杰对学术界使命的再定义,我们看到的是中国AI力量在追赶过程中的焦虑、清醒与韧性。
正如主持人李广密所言:「过去我们是在追赶,是在补课。但当科技能力追上来之后,2026年,我们期待看到中国不仅有更强的火箭,更要有自己的Payload(有效载荷)和Product(产品)。」
在ScalingLaw依然有效的今天,中国AI正在从刷榜走向落地,从复现走向探索。虽然胜算或许充满了不确定性,但正如那条被杨植麟称赞的「最美Loss曲线」一样,只要方向正确,下降就是必然的趋势。
同样重要的是,通过把自己最先进的大模型开源出来,国内科技公司正在从全球AI技术的跟随者转变为推动者。也同样是随着这个过程,在「六小虎」之后,我们已经可以逐渐看出国内AI「开源四巨头」正脱颖而出。
除了DeepSeek之外,包括智谱、月之暗面和Qwen,他们今天有三个都在台上。
结语
从杨植麟眼中那条「最美的Loss曲线」,到唐杰构想中「会做梦的机器」,林俊旸致力打造的「全能智能体」,再到姚顺雨所预言的如「间谍」般潜行的自主学习新范式,这场AGI-Next峰会为2026年的AI战事定下了基调。
过去几年,我们忙于教AI「读书」,试图将人类文明的知识灌输给它;而接下来的篇章,则是教它「做事」,让它在物理世界的真实反馈中像人一样思考、规划与行动。参数的军备竞赛或许已经降温,但关于智能本质的探索才刚刚开始。
正如几位演讲者在圆桌上的共识:智能的上限远未到达,也是那些愿意「走出榜单、寻找正确之事」的探索者们(像姚顺雨所呼吁的那样)正在努力的方向。
配资10倍的公司,配资投资服务,网上实盘配资提示:文章来自网络,不代表本站观点。